type
status
date
slug
summary
tags
category
icon
password
1. CNN
卷积核介绍
1.1. 一般卷积
一个卷积核在图像上滑动,并求取对应元素相乘求和的过程.
使用参数:
- 卷积核大小 (Kernel Size)
- 步长 (Stride)
- 填充 (Padding)
- 输入和输出通道数 (Input & Output Channels)

普通卷积公式:
- : 表示相对位置坐标 的像素值; : 表示这个像素的权重.


1.2. 扩张卷积 (空洞卷积, 膨胀卷积)
在标准的卷积核中注入空洞, 以此来增加模型的感受野 (reception field).
增加的参数:
- 扩张率 (dilation rate) 指的是卷积核的点的间隔数.

出现的原因: 在深度网络中为了增加感受野并降低计算量, 需要进行池化, 这样虽然可以增加感受野, 但空间分辨率降低了.
扩张卷积的好处: 在不丢失特征分辨率的情况下扩大了感受野, 进而对检测大物体有比较好的效果.
1.3. 转置卷积 (反卷积, 逆卷积 Transpose Convolution, Deconvolution)
有时候上采样 (使用各种插值算法) 的效果不好, 需要模型自己找到一种好的上采样方式.
常用于以下 GAN 和图像分割场景:
- 在 DCGAN 中, 生成器将会用随机值转变为一个全尺寸 (full-size) 的图片, 这个时候就需要用到转置卷积.
- 在语义分割模型中, 会使用卷积层在编码器中进行特征提取, 然后在解码层中进行恢复为原先的尺寸, 这样才可以对原来图像的每个像素都进行分类. 这个过程同样需要用到转置卷积. 经典方法如: FCN 和 Unet.
- CNN 的可视化: 通过转置卷积将 CNN 中得到的特征图还原到像素空间, 以观察特定的特征图对哪些模式的图像敏感.
对于转置卷积而言, 实际上是想建立一个与普通卷积相反的操作, 也就是建立一个一对多的关系. 比如我们想要建立的是输出卷积中的1个值与输入卷积中的9个值的关系.
- 从信息论的角度, 卷积操作是不可逆的, 所以转置卷积并不是使用输出矩阵和卷积核计算原始的输入矩阵, 而是计算得到保持了相对位置关系的矩阵.
1.4. 空间分离卷积 (spatial separable convolutions)
在空间维度将标准卷积运算进行拆分, 将标准卷积核拆分成多个小卷积核, 如下图所示:

优点: 这样做可以减小计算复杂度.
应用例: 分离的sobel算子.
1.5. 可变形卷积
可变形卷积公式
可变形卷积的输出:
- 如何获得?
- 是位置偏移量. 是训练时学习到的浮点型数值, 由图像经过普通卷积计算得到.

- 偏移后的亚像素点 转换为像素值 并 乘上各自的权重, 并且求和, 就获得了最终像素的值.
- 亚像素点的值 怎么获得?
- 找到亚像素点之后, 采样临近的4个像素点.

使用双线性插值, 求得最终的值.

- 在训练中, 通过计算损失, 反向传播和优化函数来更新 .
2. RNN
- 循环神经网络 (Recurrent Neural Network) 处理序列数据的神经网络.

- 相比一般的神经网络来说能够处理序列变化的数据, 比如上下文问题 (单词的含义因为上下文而变化).

- : 当前节点下的输入; : 上个节点的输出; : 当前节点下的输出; : 传递到下一个节点的输出.

2.1. LSTM
长短期记忆 (Long short-term memory, LSTM) 是一种特殊的 RNN, 主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题. 相比普通 RNN, LSTM 在更长的序列中表现更好.

- LSTM 与 RNN 不同之处: LSTM 比 RNN 多了一个传递状态 (cell state)
- LSTM 与 RNN 相同之处: 都有一个 (hidden state)
在传递中改变得很慢 (对于之前的 不断累积, 长期记忆), 则改变的很快 (短期记忆)
2.1.1. LSTM 详细结构
- 使用 LSTM 的当前输入 和上一个状态传递下来的 拼接训练得到四个状态.
- 将结果通过一个 激活函数来转换为 的值 (这里使用 是因为这里是将其做为输入数据, 而不是门控信号).
- 是有拼接向量乘以权重矩阵后, 再通过 激活函数转换成 到 之间的数值, 在作为门控状态.
- : 矩阵加法


: Hadamard Product (哈达玛积)
两矩阵对应的元素各自相乘

2.1.2. LSTM 三阶段
- 忘记阶段: 对上一个节点传入的输入进行选择性遗忘 (忘记不重要的, 记住重要的).
- : 控制上一个状态的 进行选择性遗忘 (forget).
- 选择记忆阶段: 对输入的 选择性记忆.
- : 当前输入内容由z表示
- : information
- 一阶段和二阶段结果相加就是
- 输出阶段: 这个阶段将决定哪些将会被当成当前状态的输出. 主要是通过 来进行控制的。并且还对上一阶段得到的 进行了放缩 (通过一个 激活函数进行变化).
2.1.3. LSTM 前向传播算法
LSTM 模型有两个隐藏状态 , 模型参数几乎是 RNN 的4倍, 因为现在多了 这些参数.
前向传播过程在每个序列索引位置的过程为:
- 更新遗忘门输出:
- 更新输入门两部分输出:
- 更新细胞状态:
- 更新输出门输出:
- 更新当前序列索引预测输出:
整体的过程如下图所示

- 在时刻, 用于计算 和
2.1.4. LSTM 反向传播算法
有了 LSTM 前向传播算法, 推导反向传播算法就很容易了, 思路和RNN的反向传播算法思路一致, 也是通过梯度下降法迭代更新我们所有 的参数, 关键点在于计算所有参数基于损失函数的偏导数.
在 RNN 中, 为了反向传播误差, 我们通过隐藏状态 的梯度 一步步向前传播. 在LSTM这里也类似. 只不过我们这里有两个隐藏状态 和 . 这里我们定义两个 , 即:
反向传播时只使用了 , 变量 仅为帮助我们在某一层计算用, 并没有参与反向传播. 如下图所示:

输出层定义的损失函数为对数损失, 激活函数为 激活函数. 因为与RNN的推导类似, 在最后的序列索引位置 的 和 为:
接着由 反向推导 , 的梯度由本层的输出梯度误差决定, 与公式 (10) 类似, 即:
而 的反向梯度误差由前一层 的梯度误差和本层的从 传回来的梯度误差两部分组成, 即:
公式 (13) 的前半部分由公式 (4) 和公式 (9) 得到, 公式 (13) 的后半部分由公式 (6) 和公式 (8) 得到.
有了 和 , 计算这一大堆参数的梯度就很容易了, 这里只给出 的梯度计算过程, 其他的 的梯度大家只要照搬就可以了。
公式 (14) 的由公式 (1), 公式 (4) 和公式 (9) 得到.
由上面可以得到, 只要我们清晰地搞清楚前向传播过程, 且只使用了 进行反向传播的话, 反向传播的整个过程是比较清晰的. 更详细 的过程可以参看参考文献【2】
在这里有必要解释下为什么反向传播不使用 , 如果与《深度学习 (五) : 循环神经网络(RNN)模型与前向反向传播算法》里一样的话, 那么 的计算方式就不应该是 (12) 式了. 因为, 参与了 和 的计算, 所以在RNN文章里的求梯度方法, 应该是
但是, 这里是一个比较复杂的时序模型, 如果使用 RNN 的思路, 将 的部分也一起反向传播回来的话, 这里的反向梯度根本无法得到闭式解. 而只考虑一个的话, 也可以做反向梯度优化, 进度下降, 但是优化起来容易的多, 可以理解为这里做了一个近似.
2.2. GRU
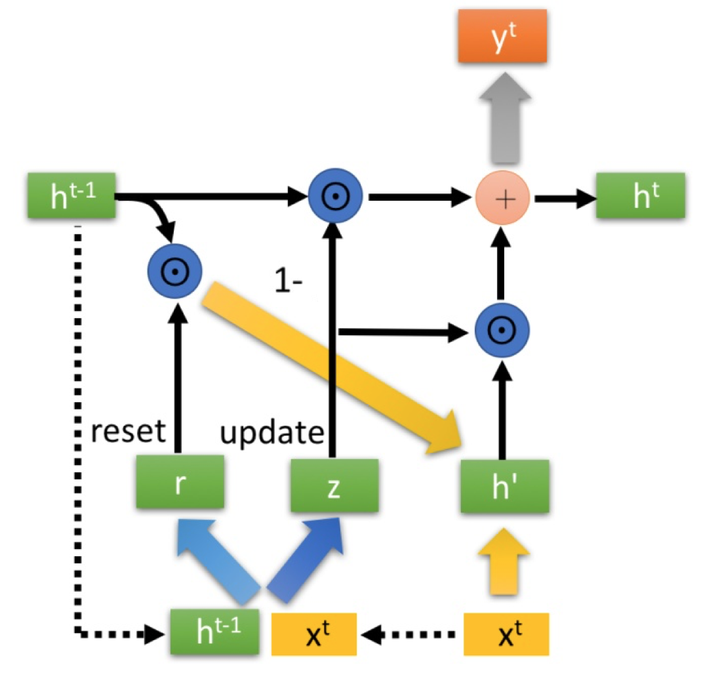
门控相较于 LSTM 减少为两个.
- 重置门控 (reset gate)

- 更新门控 (update gate)

- 首先使用重置门控来得到“重置”之后的数据 , 再将 与输入 进行拼接,再通过一个 激活函数来将数据放缩到 的范围内.

2. ”更新记忆“阶段
- 更新表达式:
- 门控信号(这里的 )的范围为0~1. 门控信号越接近1, 代表”记忆“下来的数据越多, 而越接近0则代表”遗忘“的越多.
有读者发现在 PyTorch 里面的 GRU [链接] 写法相比原版对 多了一个映射, 相当于一个GRU变体, 猜测是多加多这个映射能让整体实验效果提升较大。如果有了解的同学欢迎评论指出。
- GRU聪明的一点就在于, 我们使用了同一个门控 就同时可以进行遗忘和选择记忆 (LSTM则要使用多个门控).
- : 表示对原本隐藏状态的选择性“遗忘". 这里的 可以想象成遗忘门 (forget gate), 忘记 维度中一些不重要的信息.
- : 表示对包含当前节点信息的 进行选择性"记忆". 与上面类似, 这里的 同理 会忘记 维度中的一些不重要的信息. 或者, 这里我们更应当看做是对 维度中的某些信息 进行选择.
- : 结合上述, 这一步的操作就是忘记传递下来的 中的某些维 度信息, 并加入当前节点输入的某些维度信息. 可以看到, 这里的遗忘 和选择 是联动的. 也就是说, 对于传递进来的维度信息, 我 们会进行选择性遗忘, 则遗忘了多少权重 , 我们就会使用包含当前输入的 中所对应 的权重进行弥补 。以保持一种"恒定"状态.
2.3. BiLSTM

前向的 依次输入“我",“爱”,“中国"得到三个向量 . 后向的 依次输 入“中国”,“爱”,“我"得到三个向量 . 最后将前向和后向的隐向量进行拼接得到 , 即.
对于情感分类任务来说, 我们采用的句子的表示往往是 . 因为其包含了前向与后向的所有信息, 如下图所示:

3. Word2vec

- Word2Vec 是从大量文本语料中以无监督的方式学习语义知识的一种模型.
- 通过学习文本来用词向量来反映语义信息.
- Embedding 其实就是一个映射, 将单词从原先所属的空间映射到新的多维空间中, 也就是把原先词所在空间嵌入到一个新的空间中去.
- 隐层的激活函数其实是线性的,相当于没做任何处理 (这也是 Word2vec 简化之前语言模型的独到之处), 我们要训练这个神经网络,用反向传播算法,本质上是链式求导 (BP 算法). 当模型训练完后,最后得到的其实是神经网络的权重.
- eg: 输入一个单词 x 的 one-hot encoder, 激活隐含层里的权重, 从而得出向量 vx. 由于 x 的 one-hot encoder 各不相同, 所以vx可以用来唯一表示 x.
- gensim 和 google 的 word2vec 里面并没有用到 onehot encoder,而是初始化的时候直接为每个词随机生成一个N维的向量,并且把这个N维向量作为模型参数学习.
3.1. Skip-gram 模型
- 用一个词语作为输入, 来预测它周围的上下文

- Skip-gram 的负采样
- 对高频词采样
- stopwords 出现次数过高, 导致与之相关的训练样本都不会提供关于另一个单词的语义信息.
- Word2Vec 通过“抽样”模式来解决这种高频词问题.
- 训练原始文本中遇到的每一个单词都有一定概率被从文本中删掉, 而这个被删除的概率与单词的频率有关.
- 抽样率
- : 一个单词; 是这个单词在所有语料中出现的频次.
- 层次 所使用的哈弗曼树使用这个词频作为权重.
- 表示保留某个单词的概率; 是默认参数, 值越大, 单词被删除的概率越大.
- 负采样每次让一个训练样本仅仅更新一小部分的权重, 这样就会降低梯度下降过程中的计算量.
- 单词抽样率越高, 被删除的概率越大
- 当单词在语料中出现的频率小于 时, 它是 被保留的, 这意味着只有那些在语料中出现频率超过 的单词才会被采样. 当 时, , 意味着这一部分的单词有 的概率被保留. 当 时, , 意味着这部分单词以 的概率被保留.
eg: window = 2


3.2. CBOW 模型 continuous bag of words (连续词袋模型)
用一个词语的上下文作为输入, 来预测这个词语本身.

3.3. Word2vec 的训练 trick
- 两个降低复杂度的近似方法
- Hierarchical Softmax (层次softmax):
- 一种对输出层进行优化的策略, 输出层从原始模型的利用 softmax 计算概率值改为了利用Huffman 树 (最优二叉树) 计算概率值. 霍夫曼树优点: 比完全二叉树空间复杂度更小.
- 本质是把 N 分类问题变成 次二分类. (二叉树时间复杂度 )
- 哈夫曼树输出层不使用 one-hot 来表示, softmax 回归就不需要对那么多 0 进行拟合, 节省时间. 只需要拟合输出值到根的那条路径.
- Negative Sampling (简写 NEG, 负采样):
- Noise-Contrastive Estimation (简写 NCE, 噪声对比估计) 的简化版本: 把语料中的一个词串的中心词替换为别的词, 构造语料 D 中不存在的词串作为负样本. 因此在这种策略下, 优化目标变为了: 最大化正样本的概率,同时最小化负样本的概率. (每一个词都会被作为中心词)
- 本质是预测总体类别的一个子集.



(NCE 是一种对观测数据的概率密度进行估计的方法, 通过构造一些分布已知的 noise data, 将概率密度的估计问题转化为一个 logistic regression 问题)
4. Transformers
一些主流模型的区别

4.1. Attention Model
4.1.1. Encoder-Decoder框架
- 前大多数注意力模型附着在 Encoder-Decoder 框架下

- Encoder: 对 Source 进行编码,将输入句子通过非线性变换转化为中间语义表示 C.
- Input embedding
- Positional encoding
- 位置编码使用频率不同的正弦和余弦函数,
- 是位置; 是维度.
- 公式是位置编码每个维度对应函数曲线, 曲线波长范围: 的几何级数.
- 奇数维度用 ; 偶数维度用 .
- 选择正余弦函数是因为它可以允许模型推断出比训练期间遇到的序列更长的序列.
注意这里编码需要在在训练的时候建立一个表, 保存最细粒度字符与对应的向量, 表中的向量包括:
这就是

将位置信息 + , 变成 positional input embeddings

- Decoder: 根据 C 和之前已经生成的历史信息Target(1~i-1)来生成i时刻要生成的单词:
- 在计算 attention 的过程中, 使用一个 Q(uery), 计算它和每个 K(ey) 的相似度作为权重, 对所有的 V(alue) 进行加权求和.
- 在 self-attention 中, QKV 有 embedding 的结果经过不同的线性变换得到, 维度都是
4.1.2. Attention model
- Soft Attention model
- 上图的 E-D 模型没有 attention, 因为 Target 中每个单词生成过程如下, 是 Decoder 的非线性变换函数, 没有变化(等于人眼中没有焦点).
- 没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量 来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因.
- 目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词 的时候,原先都是相同的中间语义表示 会被替换成根据当前生成单词而不断变化的.
- 则生成过程变为
- 汤姆追逐杰瑞 → Tom chase Jerry
- f2 函数代表 Encoder 对输入英文单词的某种变换函数。
- 如 Encoder 是用 RNN model 的话
- : Source的长度
- : 在 Target 输出第 i 个单词时, Source 中第 j 个单词的注意力分配系数
- : Source 中第 j 个单词的语义编码
- 如何知道Attention模型所需要的输入句子的单词注意力分配概率分布值呢?
- 图 5 为非 Attention 模型的 Encoder-Decoder 框架, encoder 和 decoder 都使用 RNN 模型.
- 图 6 为添加注意力概率分布值的通用计算过程.
- 对于采用 RNN 的 decoder 来说, 在时刻 , 如果要生成 单词.
- 目的: 计算得到 时 source 的那三个单词对 的注意力分配概率分布.
- 通过隐层节点 时刻得到 .
- 使用 与 source 中每一个单词对应的 RNN 隐层节点状态(语义编码) 进行对比. (即 )来获得目标单词 和每个输入单词对应的对齐可能性.
- 这个 F 函数在不同论文里可能会采取不同的方法, 然后函数 F 的输出经过 Softmax 进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值.
- 如把 attention 机制从 E-D 框架剥离
- 将 Source 中的构成元素想象成是由一系列的 数据对构成.
- 给定 Target 中某个元素 Query, 通过计算 Query 和各个 Key 的相似性/相关性, 得到每个 Key 对应 Value 的权重系数. (相似计算: 点积, cosine, MLP)
- 对 Value 加权求和, 从而得到 Attention 数值.
- Self Attention model
- Attention 机制: 发生在 Target 的元素 Query 和 Source 中的所有元素之间.
- Self Attention 机制: Source 内部元素之间或者 Target 内部元素之间发生的 Attention 机制. (算 source 就是把图 9 下面的公式中的 Query 变为 Source 中的元素; 算 target 同理)

f2 函数的结果某个输入 后隐层节点的状态值
代表 Encoder 根据单词的中间表示合成整个句子中间语义表示的变换函数
函数对构成元素加权求和:
eg:
对应注意力模型权值分别是0.6, 0.2, 0.2, 所以g函数本质上就是个加权求和函数, 如图



4.1.3. Attention 机制的本质

代表 Source 长度
双竖线: 模长(向量长度)

4.2. Transformers


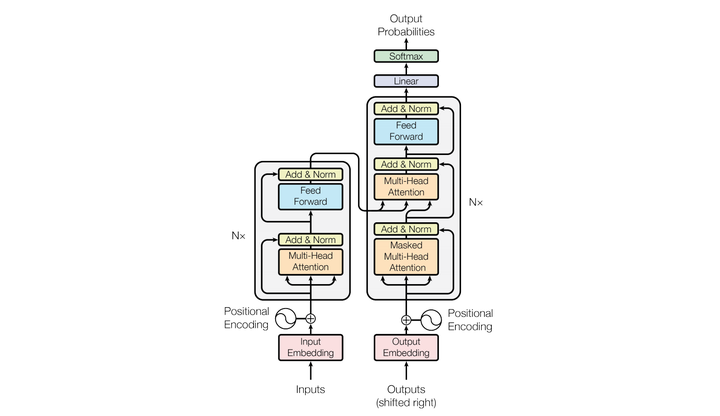


- 缩放点积注意力(Scaled Dot-Product Attention, SDPA)和多头注意力(Multi-Head Attention, MHA)


在上述注意力机制的描述中涉及了三个集合: 查询集合 Q , 键集合 K 和值集合 V. 但是, 这些集合并非一定要各不相同, 常见情况分为三种:
- 三个集合完全不同 QKV.
- 键和值集合是同一个集合 QVV.
- 即查询, 键和值三个集合实际是一回事.


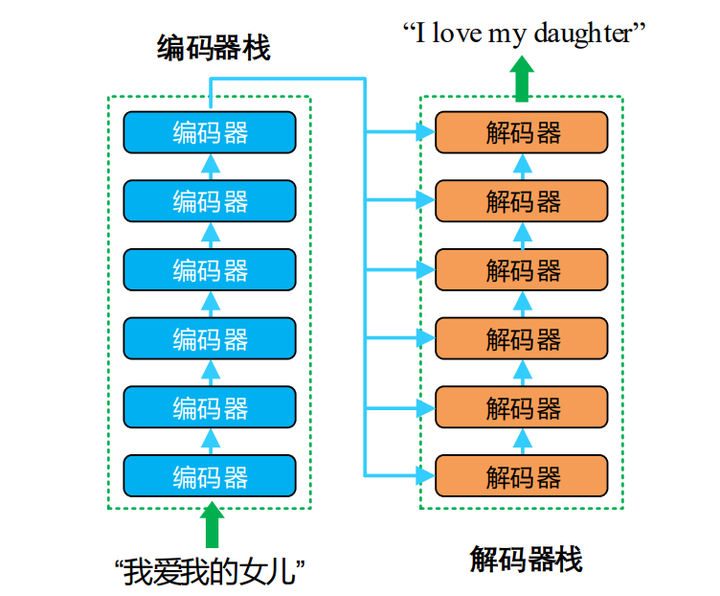
transformers 包括一个 encoder 栈和一个 decoder 栈
encoder 栈中的每个 encoder 都包含 self-attention 模块加全连接层
decoder 栈中的每个 decoder 都包含 self-attention 模块 + encoder-decoder 的 self-attention + dense layer
4.2.1. encoder self-attention 和 decoder self-attention
- encoder self-attention module
编码器自注意力模块用来捕捉输入句子中词与词之间的关系
- decoder self-attention module
不同的是添加了掩膜机制, 这是由于在解码器中, 自注意力模块只被允许处理当前项之前的那些项, 上述目标的实现方式非常简单, 只要在 softmax 注意力权重概率化之前, 用掩膜将当前处理项之后的所有项隐去即可.
加掩膜机制是为了防止预测当前位置是不会接触到未来的信息.

- encoder-decoder self-attention module
QVV 模式. Q 来自于上一个 decoder 的输出, V 来自于最后一个编码器的输出.
该注意力模块能够使得解码器中的每个项都能够有重点的 “看一遍” 输入序列中的每一个词
最后 linear + softmax
4.3. BERT
- 一种深度双向的, 无监督的语言表示.
- Masked LM(masked language model)
- 原因:
- 预测被掩盖的词, 就是一个单纯的分类问题. 根据这个位置的上下文在预测这个词, 而不是根据上一个词来预测这个词的概率(传统生成语言模型), 这种模型叫自编码语言模型 (Autoencoder LM).
- 正常的语言模型预测所有token, 所以masked LM相比正常的LM收敛的慢.
- Bert 和 Word2Vec (CBOW) 的区别
- 在预训练 (pre-training) 阶段, 模型使用 [MASK] 标签做分类任务训练, 这有点像词向量模型 CBOW, 只不过它使用更强的 Transformers 做语义特征提取器, 可以考虑到更长的上下文信息, 而不仅仅是直接取窗口长度单词之后使用浅层全连接模型做训练.
- CBOW 训练后得到的是每一个 token 的静态词向量, 而 Bert 是根据上下文信息学习出的词向量, 所以词义消歧 (WSD) 和词性标注 (POS) 表现更好.
- 为什么这么做:
- 如果只扣掉 的单词, 在 fine-tuning 的时候模型不会使用 mask 标签, 并且可能会遇到没见过的单词.
- 保留原始单词: 因为 fine-tuning 的时候的数据中所有的词都是已知的. 如果在 pre-training 的时候只用 [mask] 替换单词, 那么模型只知道根据其他词的信息来预测当前词, 而不会利用这个词本身的信息, 这样损失的信息可能不利于 fine-tuning.
- 用的随机单词替换: 如果都使用原始单词, 模型会直接照抄当前保留的词. 使用 随机单词的话, 模型无法判断这个单词在这个位置是否正确, 预测 [mask] 时迫使模型依赖上下文去预测这个单词, 可以使模型具有一定的纠错能力.
- Next Sentence Prediction
- 词嵌入 embedding
- token embedding: 词向量
- segment embedding: 句子的相对位置信息 (比如用 [SEP] 分割两个句子, 句子 2 都是 句子 2 对应的单词都是 )
- position embedding: 位置信息(单词位置, 就是 index)
- w2v 和 Bert 的区别
- Bert 和 GPT 区别
- 为什么 BERT 比 ELMo 效果好?
- LSTM 抽取特征的能力远弱于 Transformer
- BERT 的训练数据以及模型参数均多余 ELMo
- ELMo 和 BERT 的区别是什么?
- ELMo 模型是通过语言模型任务得到句子中单词的 embedding 表示, 以此作为补充的新特征给下游任务使用, 因为 ELMO 给下游提供的是每个单词的特征形式, 所以这一类预训练的方法被称为 “Feature-based Pre-Training”
- BERT 模型是基于 Fine-tuning 模式, 这种做法和图像领域基于 Fine-tuning 的方式基本一致, 下游任务需要将模型改造成 BERT 模型 (接住 Bert 模型的输出), 才可利用 Bert 模型预训练好的参数.
- Bert 的缺点
- pre-training 时, 被 mask 掉的单词之间的关系可能相互独立也可能相互存在联系.
- fine-tuning 的时候没有 mask 标签
- mask 训练慢.
- Bert 随机 mask wordpiece 分词可能会 mask 掉单词的一部分.
- word piece 分词
- 简单来说就是把单词再细分 (BPE (Byte-Pair Encoding) 双字节编码), 如: "loved", "loving", "loves" 可以变成 "lov", "ed", "ing", "es".
- 原理:
整体预训练图

随机掩盖输入单词中的 , 不像 Word2Vec CBOW 一样把每个词都预测一遍.
中 用 mask 标签替换, 用随机单词替换, 用原始单词.

在一个文章中选两句话, 判断是不是连续的 ( 概率).
符号[CLS][SEP]
训练方法不同, w2v 是单词与单词的位置关系进行训练, 计算词向量(skip-gram)
对比 OpenAI GPT (Generative pre-trained transformer), BERT是双向的 Transformer block 连接; 就像单向 RNN 和双向 RNN 的区别. GPT没有 encoder-decoder attention.
由于 Bert 是双向的, 已经知道后面要预测的词了, 所以无法做生成任务.
把一个一个字母按单词顺序放一起组合, 找出出现频率高的相邻序列, 把这个序列合并之后再组合, 循环.
4.4. Roberta
- 更多训练数据, 更大的 batch size 训练更长时间
- Dynamic Masking
- 训练同一条数据时, 会有不同 mask, 分别喂给不同 epoch
- 断句和起始符号不同
- <s></s>
4.5. GPT-2
- 使用 40G 的高质量语料库训练, 比 Bert 更大 (16G)
- 使用 wordpiece model 解决 OOV 问题(和bert相同)
- 模型是单向 transformers 的, 所以可以语言生成任务. (bert是双向 transformers; ELMo 是双向LSTM 都不能做生成任务, 因为事先知道了答案)