type
status
date
slug
summary
tags
category
icon
password
论文PDF: Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
动机
当前计算机视觉系统的构建通常依赖于预训练或随机初始化的特征提取器作为骨干网络, 而选择合适的骨干网络是一个困难的问题, 因此需要一个方法来比较不同的预训练模型, 以帮助从业者做出明智的选择.
方法
本文提出一种名为 Battle of the Backbones 的方法, 通过对一系列预训练模型进行基准测试, 包括视觉-语言模型, 自监督学习模型和稳定扩散骨干等, 涵盖了从分类, 目标检测到 OOD 泛化等各种计算机视觉任务. 通过对1500多次训练运行的全面分析, 揭示了现有方法的优势和不足, 并为研究社区指明了前进的方向.
OOD 检测任务: 在训练集和测试集非独立同分布的情况下, ODD 模型能够检测出异常样本. (能够找出训练时没有学过的样本)


优势
该方法为从业者提供了一个更加明确和全面的选择预训练模型的依据, 同时揭示了传统卷积神经网络在大多数任务上仍然表现最好, 而自监督学习模型在相同架构和相似大小的预训练数据集上也具有竞争力. 此外, 该研究还提供了原始实验结果和代码, 使研究人员能对自己的骨干网络进行测试和比较.
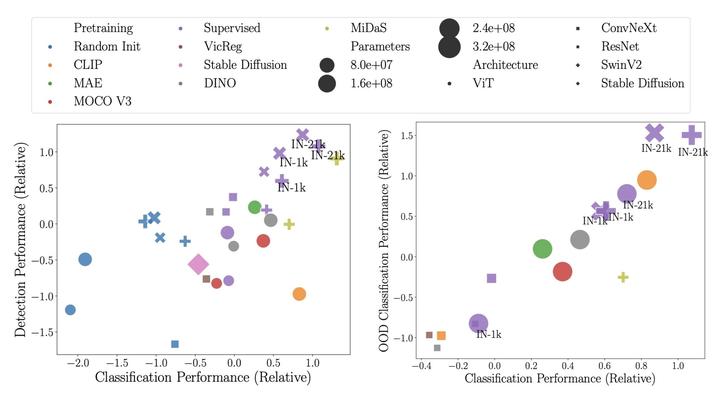
- 在分类, 检测, 分割, 域外推广和检索任务上比较了各种预训练模型的性能.
- 对于实践者来说,有监督 ConvNeXt, SwinV2 和 CLIP 的整体表现最好, 更小规模下, ConvNeXt-Tiny, SwinV2-Tiny 和 DINO ViT-Small 表现最好.
- 尽管Transformer和自监督学习越来越受欢迎, 但在大多数所考虑的任务上, 有监督卷积网络仍然优于其他方法.
- 与 CNN 相比, ViT 更依赖模型和数据集规模, CLIP 在没有大数据集的情况下也有竞争力.
- 在相似的训练设置下, 自监督学习可以优于有监督的预训练, 这意味着更先进的架构和更大的数据集可能会有帮助.
- 不同视觉任务之间的性能强烈相关, 支持通用模型.
选啥主干网络精度高?

选啥轻量化主干网络精度高?
