type
status
date
slug
summary
tags
category
icon
password
1. 行为识别 Human Action Recognition (HAR)
- 行为识别模型有两个方向: 第三人称动作识别和第一人称动作识别.
- 使用的各方向和对应的方法大致如下图, 本篇文章只介绍第三人称动作识别 RGB 模态.
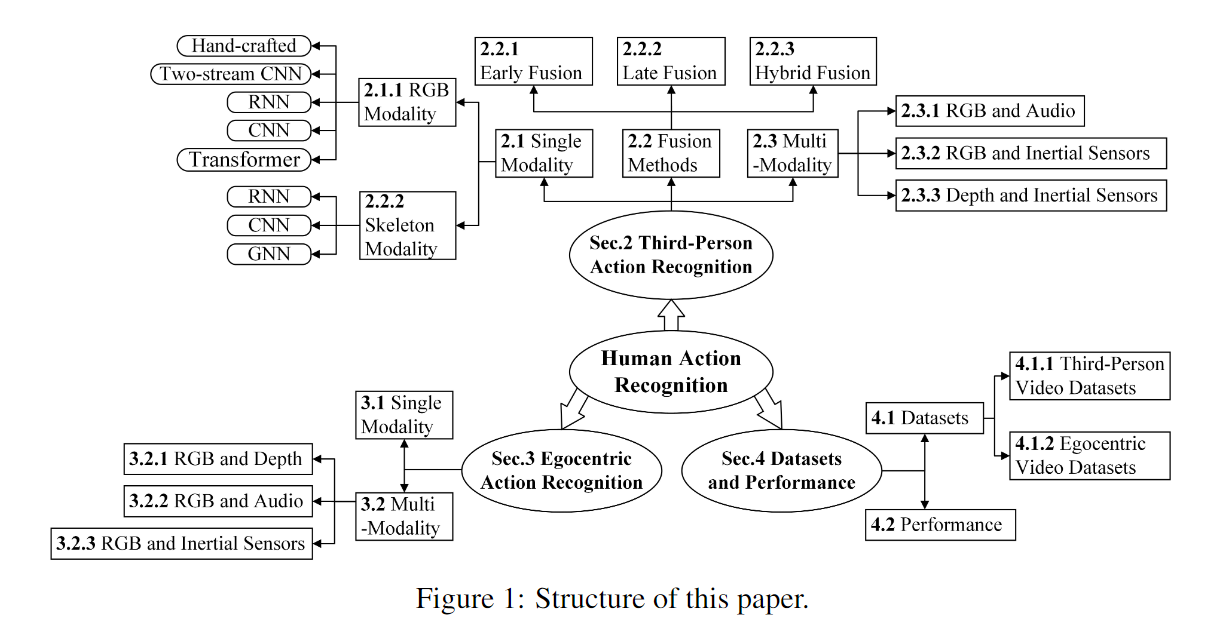
- 详细可以参考调研论文. [1]
2. 第三人称动作识别 RGB 模态
第三人称动作识别 RGB 模态方面的研究很多, 因为二维的视频数据相对来说更容易获得.


2.1. Two-stream CNN-based
双流指的是空间流和时间流, 其中空间流获得单帧图片的特征图, 时间流获得光流图 (水平分量, 垂直分量, 这里计算的是稠密的光流图, 逐像素都进行计算) 的特征图, 两者 Softmax 结果融合. [2]

- 特点是分析的是单帧图片和相邻帧获得的光流. 没有考虑较远的时间间隔帧之间的关系, 并且光流的生成消耗大量的计算性能.
- 改进
- 视频中连续帧之间的动作幅度往往很小, 所以扩大采样帧的范围, 就可以提高动作的识别几率.
- 于是本文将视频所有帧一起编码, 用来捕捉长时间范围的动作.
- 将整个视频编码为 紧凑的特征表示, 可学习语义和具有区分性的特征空间.
- 可用于 2D, 3D CNN 网络
- 不会丢失信息
- 这里将特征图按照帧顺序堆叠, 对这些特征图进行聚合运算. (方法有三种: 逐元素求平均, 逐元素求最大值, 逐元素相乘. 其中逐元素相乘效果最好)
- 将获得的时间聚合矩阵 (temporal aggregated matrix) 输入编码器, 获得线性编码特征向量 .
- 公式: , 表示权重; 时间和空间流特征图的时间聚合矩阵; 表示外积; 方括号表示通过连接列, 将矩阵变为向量. 这种方法比全连接池化参数量少并且效果好.
时间段网络 TSN [18], 一个输入视频被分为 个片段, 并且从每个片段中随机选择 1 帧.

残差双流架构 (Two-stream ResNets) [4] (允许时间流信息流向空间流)



在卷积层后加时空线性编码 (temporal linear encoding TLE) 模块 [6]
TLE 的优势在于:


使用的编码器双线性编码器.


- 双流 CNN 方法的优点是在数据较少的情况下, 光流直接作为输入传递给时间流, 这样动作的特征更容易学习. 所以在数据较少的情况下, 双流 CNN 比 3D CNN 效果更好. [3]

光流图如何生成?
- 光流式空间运动物体在观察成平面上像素运动的瞬时速度, 是利用图像序列中像素在时间域上的变化. [5]
- 光流图的生成需要两个假设
- 假设相邻帧之间光的亮度不变
- 假设领域光流相似
- 传统方法有 稀疏光流估计算法 (Lucas Kanade Method) 和 稠密光流估计算法 (Gunnar Farneback Method). [7] 传统稠密光流估计函数
cv2.calcOpticalFlowFarneback, 性能由于稀疏光流估计, 但是速度较慢, 50w ppi 视频 CPU 9.75 fps; CUDA 170.22 fps - 其中
- 是沿横轴的图像梯度, 是沿纵轴的图像梯度, 是沿时间的图像梯度.
传统的光流估算方法介绍
假设一个物体的亮度为 , 它移动到了 和 处, 此时亮度为 . 假设两帧之间的亮度不变, 则
移动后亮度使用泰勒近似可以获得
将公式 (1) 带入公式 (2)
取消相同项可以获得
两边除以 就可以获得光流方程
转换为矩阵形式
这里需要计算每个像素点的 这两个向量 (光流的水平分量和垂直分量), 两帧之间的时间 已知, 但是只有一个公式是无法算出两个未知量的.
这里需要用到领域光流相似的假设. [7] 就是以某一点为中心, 设定的 (如 3x3) 领域内所有像素点光流值一致.

上面的公式是 的形式, 可以求得光流 的最小二乘解.
但是必须要求 可逆, 否则公式 (4) 会出现多个解, 即孔径问题 (Aperture problem), 如下图, 相邻帧从圆孔中观察条纹变化, 发现没有变化, 从而无法计算出光流方向.

所以, 亮度变化明显的角点更容易被计算出光流.
深度学习方法: FlowNet 性能低于传统方法; FlowNet2 [10] 性能追平传统方法, 并且速度很快


- 稀疏光流估计算法做了两个假设: 1. 亮度不变, 假设前后两帧同一物体亮度不变; 2. 领域光流相似, 假设一个像素点周围的8个像素点的移动方向与该像素点一致.
2.2. 3D CNN-based
将具有空间维度和时间维度的视频帧一起输入 3D CNN 网络中. 可以更好的获取到视频中的时间信息 [9]. 但是 3D CNN 的计算成本高于 2D CNN (不包括光流图的计算).

- 优化方案
- 网络
- 网络末尾做了一个自适应池化
nn.AdaptiveAvgPool2d(1), 将结果拉成了一维, 用nn.Linear(feature_dim, num_class))作为全连接层, 最后softmax分类. - 视频帧采样, 使用 long-range temporal 采样策略. 就是将视频均分为 等分. 每一份片段中随机采样 1 帧 (这个和 TSN 一样), 获得网络输入 .
- Temporal Shift Module (TSM)
- 本论文最重要的贡献就是 TSM. 通过网络结构图可知, 每张图片都经过 Conv-2D, 获得的是一组按时间排列的二维特征图, 问题是为什么 TSM 能够实现在 Conv-2D 上对时空双方进行建模呢?
- Shift: 对于矩阵 tensor(T*C*H*W) C=3, TSM 沿着时间 (temporal) 维度移动部分的通道 (比如bi-direction 进行了时间维度上的 shift +/- 1), 使得每个时间维度上的矩阵 tensor(C*H*W) 能够获得相邻帧的特征 (一般通道只有三条, 所以一条后退 1 帧, 一条前进 1 帧, 一条不动), 在时间维度上感受到 3 (-1 0 +1)帧的范围.
- Multiply-accumulate(乘法累加): 假设有一维卷积, kernel size 为 3, 则 , 卷积算子 , 假设输入是一维向量 (单通道), 算子的输出可以被写为 .
- 举例来说, Shift 移动的 3 个位置 分别乘以这三个权重, 乘法累加的总和为 (输出)
- 但是这样简单的位移策略效率和性能都不高.
- 模块的优化方案
- 使用残差位移, 在残差分支内融合时间维度信息.
- 对于实时的视频来说, shift 就只能单向了, 因为后一帧是未知
- 性能和效率
- 预处理
- 稀疏采样, 将视频分为 个区域, 在每个区域中随机采样一帧.
- 密集采样, 采样稀疏采样帧的前后的连续两帧, 就是一共连续 5 帧的密集采样.
- 网络结构
- 短期时差模块 (S-TDM) 连续帧上的时间差异用于为 2D-CNN 提供更精细的运动模式. 因为只用单帧无法获得局部的运动信息.
- 在相邻帧之间作差, 并堆叠起来用单一尺度的卷积层计算特征, 并与中间的那一帧的特征做融合. 这样就可以获得短期运动信息.
- 这里对连续帧之间的差值, 做了平均池化+堆叠+卷积 (这么做是为了提升效率), 论文中说, RGB 差异在运动区域非常明显, 所以特征在低分辨率下也不会有太大损失.
- 但是, 这个模块获得的特征无法学习到长期的运动信息.
- 长期时差模块 (L-TDM) 用较大时间间隔的短期运动信息来获得长时间的运动特征.
- L-TDM 是双向的, 多尺度的注意力机制.
- 双向是指: 对相邻的局部运动特征
- 由于间隔时间较大, 相邻的片段之间的空间位置可能没有对齐.
- 通过相邻的片段来计算对齐的时间差
- 表示 对齐的时间差, 是用于空间平滑的通道卷积.
- 使用三个尺度的特征信息相融合获取长时间间隔的运动特征.
TSM [8a][8b] 提供了一种既高效, 性能又好的模块. 这个模块可以注入 Backbone, 后面可以接行为识别或者物体检测 (用于应对运动模糊, 遮挡, 失焦等问题), 这个论文用的是二维卷积, 但是达到了三维卷积的效果.





TDN [17] 提出了一种时间差分网络 (Temporal Difference Networks), 利用时间差分算子来设计有效的时间模块 (TDM). 为了充分捕捉视频的信息, TDN 使用了两级差分建模.



2.3. RNN-based
使用 LSTM 或变种, 输入一般和双流一样, RGB帧 + 光流图, 如 [11], 网络结构如下

也有不使用光流图的, 如[12], 但是性能上不如较新的有光流图的网络结构.
总之由于使用了 RNN 网络, 使模型的效率降低, 所以 RNN-based HAR 论文中一般都不会去标出效率指标.
2.4. Transformer-based
将 ViT (用于图片分类的 transformer 模块) 扩展到了视频, 将视频分解成一连串帧级别的块, 使用分割注意力机制, 在模型的每个块内分别应用空间和时间的注意力. [13]


ViViT [14] 从视频中提取时空特征, 通过变换层进行编码.




RViT 进行了效率优化, 它的 FLOPs 与 TSM 和 TDN 是相同级别, 并且性能高于 TDN. 目前平衡性能和效率的最佳选择. [16]
RViT 在变压器中采用递归机制来实现视频动作识别任务. 这个机制导致了性能, 效率的提升并且降低了显存使用量.


