type
status
date
slug
summary
tags
category
icon
password
1. Logistic Regression
模型介绍
- 逻辑回归 (Logistic regression) 是分类模型, 常用于二分类.
- 逻辑回归的本质是: 假设数据服从分布, 然后使用极大似然估计做参数的估计
- Logistic 分布是一种连续概率分布
- 分布函数:
- 密度函数:
- : 未知参数; : 形状参数.
- logistic 分布的形状与正态分布的形状相似, 但是Logistic 分布的尾部更长, 所以我们可以使用Logistic 分布来建模比正态分布具有更长尾部和更高波峰的数据分布.
- Sigmoid 函数就是Logistic 的分布函数在的特殊形式.

- Logistic 回归
- Logistic 回归主要用于分类问题, 如二分类, 对于所给的数据假设存在一条直线可以将数据完成线性可分.
- 先看决策边界 (decision boundary) 问题
- 有线性决策边界(linear decision boundaries) 可以表示为 , 假设某个样本点 那么可以判断其类别为1, 这个过程就是感知机.
- 非线性决策边界(non-linear decision boundaries)
- Logistic 回归还需要找到分类概率与输入向量 的直接关系, 然后通过比较概率值来判断类别.
- 考虑二分类问题, 给定数据集:
- 由于多元线性回归模型(单调可导函数) 的取值是连续的, 所以不能拟合离散变量, 但可以用它来拟合条件概率, 因为概率的取值也是连续的. 而概率的取值范围是[0, 1], 所以使用广义线性模型.
- 最理想的模型是单位阶跃函数:
- 常用的函数是sigmoid函数, 将
- 所以输出的对数几率是由输入的线性函数表示的模型, 这就是逻辑回归模型.


但是这个模型不单调, 所以不可导(不连续不平滑), 所以不是广义线性模型
,
此时是一个概率(0到1之间), 设y为x的正例概率, 1-y为x的反例概率, 两者的比值为几率 (odds).
这里
2. Support Vector Machine(SVM)
支持向量机(英语:support vector machine,常简称为SVM,又名支持向量网络)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
- SVM有三种不同的模型:
- 线性可分SVM
- 线性SVM
- 非线性SVM
当训练数据线性可分时, 通过硬间隔(hard margin)最大化可以学习得到一个线性分类器(硬间隔SVM)
当训练数据不线性可分但近似可分时, 通过软间隔(soft margin)最大化可以学习得到一个线性分类器(软间隔SVM: 允许少量样本不满足约束).
当训练数据不可分时, 通过使用核技巧(kernel trick)和软间隔最大化可以学习到一个非线性SVM.
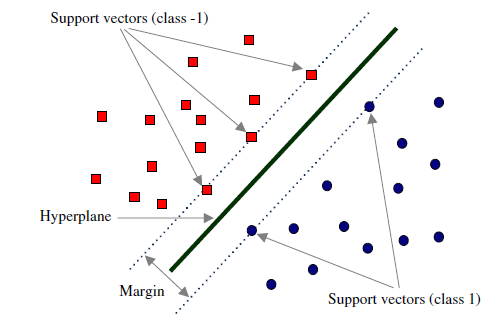
- 支持向量 (Support vertor)
- 在线性可分的情况下, 训练数据集的样本点中与分离超平面距离最近的数据点叫支持向量, 比如, 假设一个超平面是, 这个点在上.
- 移动或删除非支持向量都不会对最优超平面产生影响, 即支持向量对模型起着决定性作用, 所以这个方法叫支持向量机.

- 软间隔最大化
软间隔允许少量样本不满足约束
- 惩罚参数C
- , 禁止分类误差样本存在, 就是硬间隔SVM.(过拟合)
- , 不再关注分类是否正确, 只要求间隔越大越好, 训练无法收敛.(欠拟合)
C调节优化方向中两个指标(间隔大小, 分类准确度)偏好的权重.
软间隔SVM相对于硬间隔SVM, 适当放宽了margin的大小, 容忍了一些分类错误(当做噪声处理)
- 核技巧 (kernel trick)
- 使用一个变换将原空间的数据映射到新空间(如更高维度甚至是无穷维度空间)
- 在新空间里用线性方法从训练数据中学习得到模型.
核技巧原理:
- 总结
任何算法都有其优缺点,支持向量机也不例外。
支持向量机的优点是:
由于SVM是一个凸优化问题,所以求得的解一定是全局最优而不是局部最优。
不仅适用于线性线性问题还适用于非线性问题(用核技巧)。
拥有高维样本空间的数据也能用SVM,这是因为数据集的复杂度只取决于支持向量而不是数据集的维度,这在某种意义上避免了“维数灾难”。
理论基础比较完善(例如神经网络就更像一个黑盒子)。
支持向量机的缺点是:
二次规划问题求解将涉及m阶矩阵的计算(m为样本的个数), 因此SVM不适用于超大数据集。(SMO算法可以缓解这个问题)
只适用于二分类问题。(SVM的推广SVR也适用于回归问题;可以通过多个SVM的组合来解决多分类问题)
Reference

3. TF-IDF算法
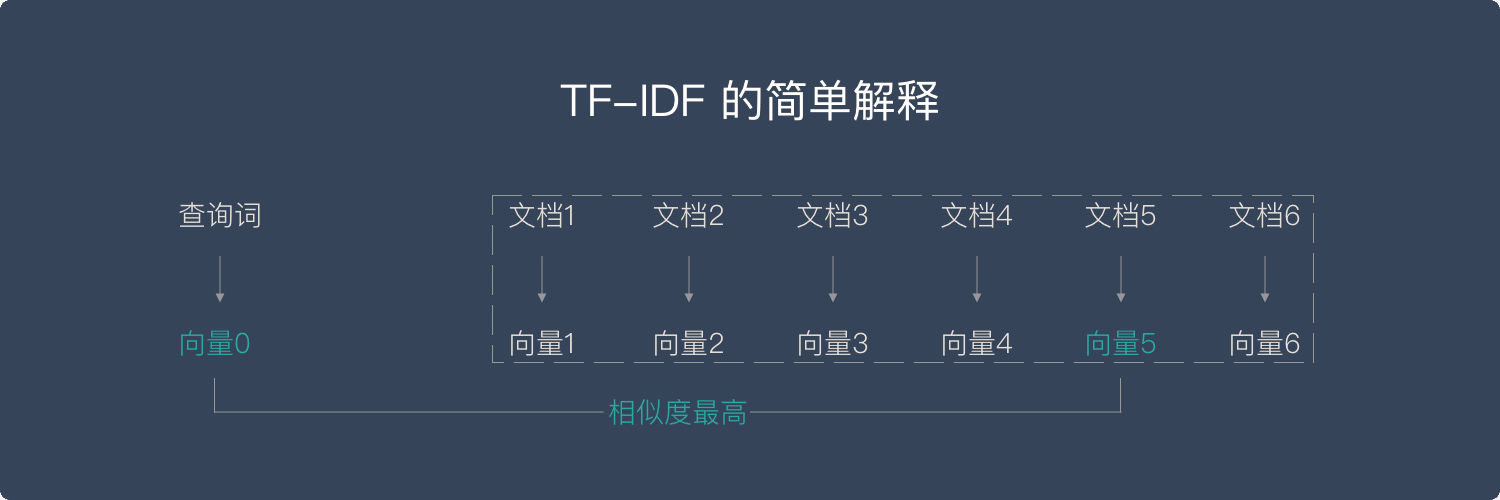
- 向量空间模型就是希望把查询关键字和文档都表达成向量,然后利用向量之间的运算来进一步表达向量间的关系
- 优点: 简单快速
- 缺点: 用词频来衡量文章中的词的重要性不够全面.
3.1. TF (Term Frequency)—— “单词频率”
- 某个关键字在文档中出现的次数
- 问题: TF不能完整的描述文档的相关度. eg. 停词
- 于是需要IDF
3.2. IDF(Inverse Document Frequency)—— “逆文档频率”
- 惩罚 (Penalize)那些出现在太多文档中的单词。
- 真正携带 “相关” 信息的单词仅仅出现在相对比较少,有时候可能是极少数的文档里. 所以使用DF的倒数来表示.
- 文档频率 (DF): 有多少文档涵盖了这个单词. 如果有太多文档都涵盖了某个单词, 这个单词也就越不重要, 或者说是这个单词就越没有信息量.
3.3. TF-IDF的4个变种
- 通过对数函数避免 TF 线性增长
- 由于TF值的增长没有上限, 某个单词在一个文档中的TF相对的来说表达了某种相关度. 超过了某个阈值之后这个TF就没什么区分度了.
- 所以使用Log函数对TF进行变换, 使其不线性增长.
- eg: 假设 “Car” 出现一次,新的值是 1,出现 100 次,新的值是 5.6,而出现 200 次,新的值是 6.3。
- 标准化解决长文档、短文档问题
- 根据文档的最大 TF 值进行的标准化(Normalization).
- eg: 一个文档 A 有 3,000 个单词,一个文档 B 有 250 个单词,很明显,即便 “Car” 在这两个文档中都同样出现过 20 次,也不能说这两个文档都同等相关。
- 对数函数处理 IDF
- Log函数对IDF进行变换.
- 相对于直接使用 IDF 来作为惩罚因素, 可以使用 N+1 然后除以 DF 作为一个新的 DF 的倒数, 并且再在这个基础上通过一个对数变化. 这里的 N 是所有文档的总数.
- 优点1: 使用了文档总数来做标准化, 类似于方法2.
- 优点2: 利用对数达到非线性增长的目的. 方法1.
- 查询词及文档向量标准化
- 使向量能够不受向量里有效元素多少的影响. 不同长度的文档, 标准化为单位向量. 此时点积运算, 就等于在原向量上进行余弦相似度运算.
3.4. 运算过程
eg:
一个包含O个单词的文档中出现单词x P次.
总共M个文档, 其中N个文档中存在单词x.
分母+1是为了避免分母为0的情况.
4. K-means
基于欧式距离的聚类算法, 其认为两个目标的距离越近, 相似度越大。
- 算法步骤
- 选择初始化的k个样本作为初始聚类中心:
- 针对数据集中每一个样本, 计算它到每个聚类中心的距离, 将其分到距离最短的聚类中心所对应的类中
- 针对每一个类, 重新计算它的聚类中心, 该类的所有样本的质心
- 重复上两个操作, 直到某个终止条件(迭代次数, 最小误差变化)
- 优点
- 简单算法复杂度低, 聚类效果好, 虽然是局部最优, 有时候局部最优就够了
- 处理大数据集时, 可以保证较好的伸缩性
- 当聚类分布近似高斯分布的时候, 效果好
- 缺点
- k值需要人为设定, 不同k值结果不同, 结果好坏需要人为判断(手肘法(k-sum of distance的曲线趋于平缓时, 那个拐点就是最佳值 ), gap statistic,)
- 对异常值敏感
- 样本点只能被划分到单一的一个类中.
- 不太适合太离散,类别不平衡, 非凸形状的分类
- 使用欧式距离计算邻居之间的距离
- 不能使用曼哈顿距离. 因为曼哈顿距离只能计算水平或垂直距离, 而欧氏距离可以计算任何空间里的距离
5. 常见机器学习模型
5.1. LR模型 (sigmoid函数 范围(0, 1))
- 为什么 LR 需要归一化或者取对数;为什么 LR 把特征离散化后效果更好?
- 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 稀疏向量内积乘法运算速度快
- 离散化后的特征对异常数据有很强的鲁棒性, eg: 分年龄段
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合
- 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
- 为什么LR需要归一化或者取对数?
- 归一化:可以提高收敛速度,提高收敛的精度;
- 为什么LR把特征离散化后效果更好?离散化的好处有哪些?
- 逻辑回归属于广义线性模型,表达能力受限; 在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
- 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
- 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
- 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
- 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
5.2. Random forest (随机森林)
- 随机森林是由很多决策树构成的,不同决策树之间没有关联。
- 优点
①训练可以高度并行化,可以有效运行在大数据集上。
②由于对决策树候选划分属性的采样,这样在样本特征维度较高的时候,仍然可以高效的训练模型。
③由于有了样本和属性的采样,最终训练出来的模型泛化能力强。
④可以输出各特征对预测目标的重要性。
⑤对部分特征的缺失容忍度高。
⑥袋外数据可用作验证集来检验模型的有效性,不用额外划分数据集。
- 缺点
①在某些噪声比较大的样本集上,随机森林容易陷入过拟合。
②取值划分比较多的特征容易对随机森林的决策产生更大的影响,从而影响拟合的模型效果。
- CART(Classification and Regression Tree 分类回归树)
- 连续特征
- 使用基尼系数将连续的特征离散化.
- RF 和 GBDT 的区别
- 组成随机森林的树可以是分类树,也可以是回归树;而GBDT只由回归树组成
- 组成随机森林的树可以并行生成;而GBDT只能是串行生成
- 对于最终的输出结果而言,随机森林采用多数投票等;而GBDT则是将所有结果累加起来,或者加权累加起来
- 随机森林对异常值不敏感,GBDT对异常值非常敏感
5.3. GBDT (Gradient Boosting Decision Tree)
- 梯度提升
- 串行, 弱分类器累加
- 基于经验损失函数的负梯度来构建新的决策树, 构建完后再进行剪枝.
- GBDT 和 XGBoost 的区别
- 集成学习
- boosting
- 训练各基分类器是使用串行方式, 各个基分类器之间有依赖
- 在每一层训练时, 对前一层基分类器分错的样本给予更高的权重.
- bagging
- 并行
- 投票的方式得出结果
5.4. XGBoosting
- 在决策树构建阶段就加入了正则项, 用于控制模型的复杂度, 降低模型方差, 防止过拟合
- 列抽样. 学习RF使用列抽样. M个特征中取m个
- 支持过多的基分类器, eg: 线性分类
- 可以使用二阶导数(和一阶)
- 支持特征粒度上的并行, 在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,可以大大减小计算量。(决策树的学习中最耗时的一个步骤就是对特征的值进行排序)
- 贝叶斯优化?