type
status
date
slug
summary
tags
category
icon
password


1. Installation
2. Tensor Basics
- tensor格式是专门为cuda准备的
- tensor和np.ndarray 相互转换时, 变量的内存共享, eg: 使用add_, 都会变.
- numpy格式无法放入显存
- 选定显卡
3. Autograd

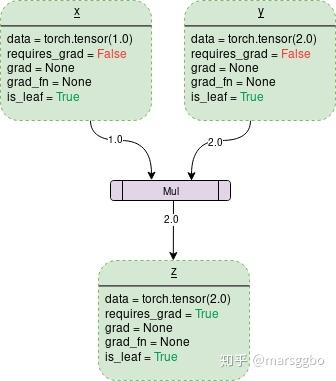
- 注意, loss必须是标量, 才能进行反向传播. 所以如果loss是向量, 需要用sum或mean将loss转换为标量.

- 每个epoch训练之后都要使w的grad清零:
4. Backpropagation


5. Gradient Descent With Autograd and Backpropagation
Training Pipeline: Model, Loss, and Optimizer
- 类里的super是干嘛的?
- 可以调用基类里的方法, 如果调用C类的话, 会再super处自动调用A类
6. Linear Regression

7. Logistic Regression
8. Dataset
8.1. DataLoader
- 使用
torch.utils.data.DataLoader()调用数据 - DataLoader方法结合了数据集和取样器, 可以自动对数据进行shuffle, mini_batch, 多线程, 自定义预处理方法等功能, 非常方便.
8.2. Dataset Transforms
- 对数据进行预处理的时候该怎么做?
- 特殊函数 __call__和__init__ 类似, 不同之处:
- 在创建实例的时候__init__会被调用, __call__不会.
- 对实例进行输入的时候, __call__才会被调用.
9. 激活函数
9.1. Sigmoid
二分类问题可以用sigmoid函数(又称Logistic函数). 可以将范围的数值映射到之间. 所以可以表示为概率. 公示如下:
9.2. Softmax
多分类问题可以使用Softmax, 公示如下:
9.4. Activation Functions
常见的激活函数
- step function
- sigmoid
- tanh
- ReLU
- Leaky ReLU
- softmax
10. Loss 损失函数
10.1. Cross Entropy
- 通常分类问题使用Softmax或Sigmoid函数获得每一个分类的可能的概率.

- 公式推导过程
- 表示训练样本数; 表示分类数量. 因为只要找到最值就可以了, 所有这里是额外加一个的. 利用似然函数的特性, 把连乘提到左边变成连加; 加上负号求最小值.


- 如果使用
nn.CrossEntropyLoss()就不要再网络最后加Softmax层, 但是如果使用nn.BCELoss(),网络最后要加上Sigmoid层.

- 如果网络是多分类问题, 就是用
nn.CrossEntropyLoss()

- 如果网络是二分类问题, 就是用
nn.BCELoss(), 网络最后需要使用sigmoid函数.

11. Feed-Forward Neural Net

12. Convolutional Neural Net (CNN)
13. Transfer Learning
14. Tensorboard
- 启动tensorboard
MAC终端连接ssh,将服务器的6006端口(或者其他没有被占用的端口都行,比如6007…)重定向到自己机器上来,在本地终端,输入以下命令:
说明:16006:127.0.0.1代表自己机器上的16006号端口(这个端口号应该也是自己改的,只要是本地没有被占用的就可以),6006(或者其他服务器上没有被占用)是服务器上tensorboard使用的端口。username指的是服务器的用户名;remote_server_ip指的是服务器的IP。
在服务器终端输入以下命令:
需要在工程文件夹下执行
在本地浏览器输入以下地址便可访问:
127.0.0.1:16006/
- code
show image

show model graph

show loss
15. Save and Load Models
- model.eval()的作用
- 有些model中存在dropout layers或BatchNorm layers, 这些layers在evaluation的时候是不使用的, eval()函数可以关闭这些layers.
- eval()在validation和test时都不会进行梯度下降.(无需使用torch.no_grad())
- 如果之后还需要训练, 使用train()函数.
- 查看model权重